
Metodología
Tras ver que el enfoque usado para detectar las frutas en la imágen era bastante distinto dependiendo del tipo de la misma, y que no se podía generalizar en un único método válido para las 6, se decidió separar el problema en 2 partes.
- Clasificación: Está parte consiste en, dada una imágen sin ninguna etiqueta, identificar cuál de las 6 frutas está presente en la imágen.
- Detección: En está etapa, ya conocida cual es la fruta que aparece en la imágen, se buscará detectar la cantidad y posición de todas las frutas que haya en la bandeja.
Para la clasificación se consideraron dos posibles enfoques, Random Forest y Red Convolucional.
Random Forest con características de la imágen
Este primer método más apegado a las herramientas del curso plantea la siguiente cadena de procesamiento para poder extraer características relevantes de la imágen que nos ayuden a clasificar según la fruta.
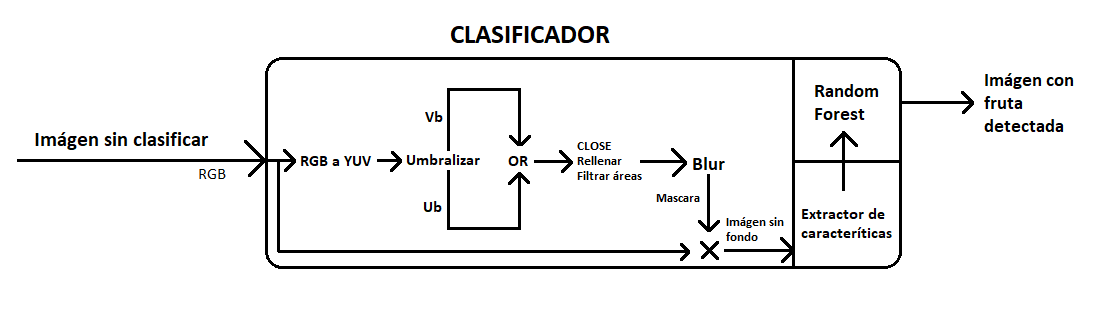
Diagrama del clasificador
-
Escala de color:
Pasar la escala de color de RGB a YUV. Esto debido a que el fondo de las imágenes (la bandeja) es plateada (gris, sin color), y las frutas generalmente tienen una componente de color (salvo las ciruelas que son casi negras); por lo tanto se buscó pasar a una escala de color donde se separe la intensidad del color. Esto fue inspirado en la forma en que la televisión analogica solía enviar la señal en color, enviando por una parte la intensidad (señal Y, imágen blanco y negro) y por otra parte las dos componentes de color (U y V). Si bien también se probaron otras escalas, por ejemplo HSV como sugerían otros trabajos con objetivos similares, al final se observó cualitativamente que era mejor usar los canales U y V. -
Umbralizado:
Se realiza una umbralización de Otsu sobre estos dos canales. El objetivo de esta umbralización es separar la fruta del fondo en función de lo que se comentó antes de la ausencia de color del fondo, que hace que en estos canales sea fácil distinguir el fondo de la fruta. Luego se toma el OR pixel a pixel entre las dos imágenes umbralizadas para obtener información de los dos canales y hacer una binarización más robusta. -
Operaciones morfológicas:
Debido a las manchas de luz presentes y a otras imperfecciones de la imágen, las imágenes binarizadas pueden presentar huecos o manchas no deseadas, por eso en esta etapa utilizaremos operaciones morfológicas para sanear estos defectos. Primero un OPEN para eliminar pequeñas manchas dispersas en el fondo, y luego se rellenan huecos para eliminar justamente los huecos que pueden aparecer en las frutas. Se probó con distintos elementos estructurantes para mejorar el desempeño en ciertos tipos de oclusión para separar pequeños cabos, sin embargo los mejores resultados se dieron con un núcleo uniforme. -
Filtrado por área y suavizado:
Para eliminar pequeñas manchas que aún persisten, se filtra por área, eliminando las regiones que no tengan cierta área mínima determinada experimentalmente a partir de la fruta más pequeña..
Los bordes de la imágen binarizada se suavizan aplicando un Blur con un filtro de mediana. Y se obtiene finalmente una imágen binarizada que sirve como máscara de donde hay fruta y dónde fondo. -
Extracción de características:
Utilizando la máscara se puede calcular ahora el color medio (en RGB, vector de 3 dimensiones), y también calcular otras características de los bordes de la imagen binarizada, por ejemplo los que se terminaron utilizando fueron: área y perímetro de la sección más chica detectada (buscando que sea una fruta separada y no la oclusión de varias) , y circularidad de la misma (con el objetivo de medir que tan redonda o no es la fruta).
Hecho este proceso se puede obtener para cada imágen entonces un vector de 6 características que busca distinguir a las frutas (justamente 6 también). Entonces entrenamos un Random Forest con los vectores de cada fruta del subset (usando como etiquetas el tipo de fruta). Se decidió usar un Random Forest sobre otros como KNN o SVM debido a su robustez y la interpretabilidad que brinda.
Usando esta técnica se alcanza un rendimiento del 90% de acierto, teniendo las mayores confusiones con las ciruelas, para las cuales el proceso de separación del fondo no es tan efectivo.
Red Convolucional
Por otro lado, en Kaggle junto con la base de datos (que estaba asociada a una competencia de
clasificación) hay una red convolucional de no mucha complejidad, ya entrenada, capaz de obtener
una tasa de acierto de un 99.9% (sobre la variedad original de 16 frutas).
Utilizando la arquitectura de esta red, se entrenó un modelo para detectar únicamente las frutas
concernientes a nuestro problema siendo esta nuestra segunda opción para el clasificador.
Si bien la primera opción está más apegada a lo tratado en el curso, la segunda obtiene un desempeño mucho mayor y con el objetivo de no introducir un cuello de botella para la segunda etapa (detección) optamos por usar la red convolucional y suponer entonces que el error final obtenido será el cometido en la etapa de detección (que es en la que más nos enfocaremos) y no en la de clasificación.